참고
https://www.youtube.com/watch?v=mlsZIThxQcQ
https://arxiv.org/abs/2404.16130
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on gl
arxiv.org
https://arxiv.org/pdf/2501.00309
1. Backgrounds
- 전체 text corpus를 아우를 수 있는 Query-Focused Summarization 태스크에 적합한 RAG 시스템 구축하자
- Query-Focused summarization : Corpus의 전반적인 내용을 반영해야만 답변이 가능한 경우
ex) 이 데이터셋의 전반적인 주제, 테마는? 지난 10년간 연구 중 중요 트렌드는? - 코퍼스 전반적인 이해가 있어야 답변 가능한 질문 -> Query-Focused Summarization
- Query-Focused summarization : Corpus의 전반적인 내용을 반영해야만 답변이 가능한 경우
- 키워드 : RAG, Knowledge graph, Community detection, Sensemaking
RAG
- 믿을 수 있는, 신뢰할 수 있는 자료로 DB를 구축하고, 이를 이용하여 LLM으로 하여금 질문에 대한 답변 생성
- 구성 요소
- DB : 검색 대상의 문서 전체 집합 / Indexing : 문서들을 chunking한 후 임베딩 모델을 이용하여 벡터화 한 후 저장하는 행위
- Retriever : DB에서 질문과 가장 관련성 높은 문서를 탐색하는 모듈
- Generator : Retriever로부터 탐색된 문서와 query를 기반으로 답변을 생성하는 모듈
- 일반 RAG의 초점은 질문의 의도 분석 및 질문과 연관있는 문서를 어떻게 탐색할 것인가에 초점
- DB 내 문서간 관계, 연결성에 대해서는 비교적 낮은 관심
Knowledge Graph
- Knowledge Graph : Knowledge Base를 그래프로 나타낸 것
- Knowledge Base : 서로 다른 두 객체의 소속(종류) 및 두 객체 간 관계를 담은 지식 정보
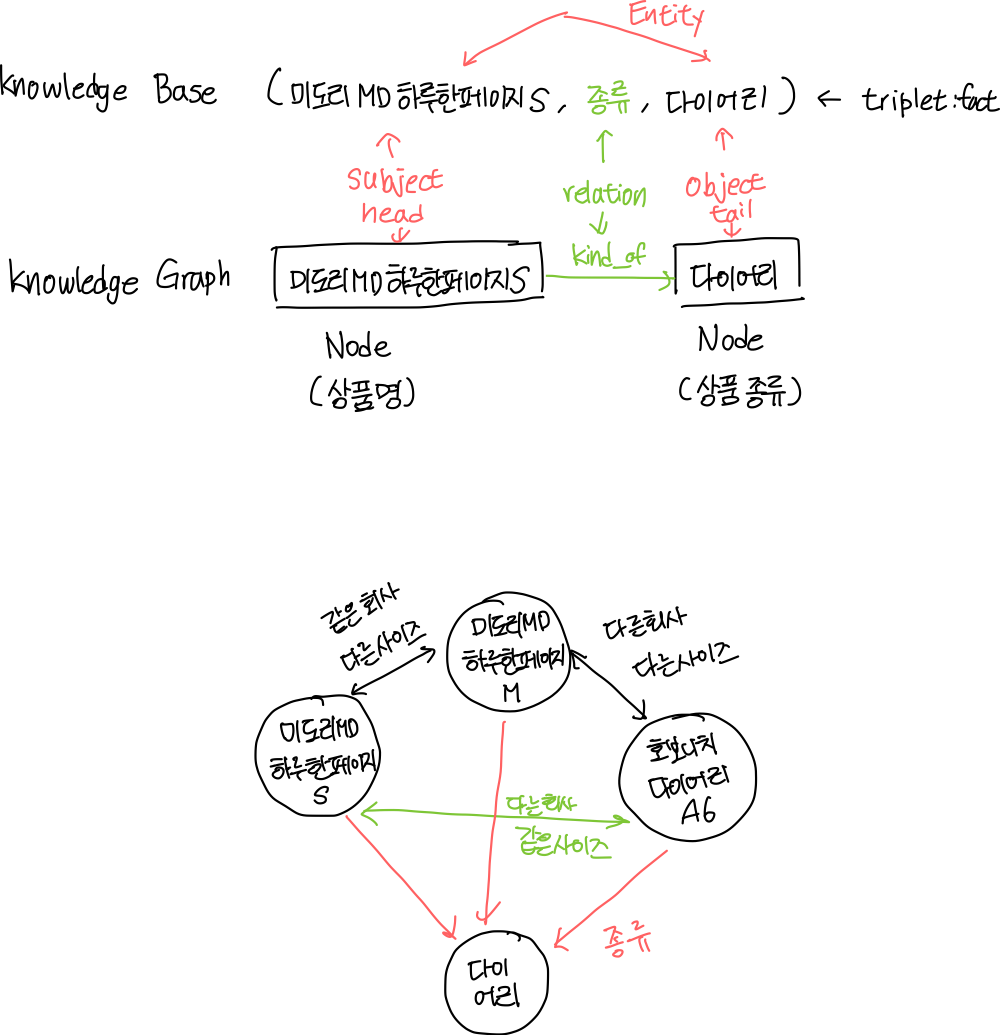
- DB로서 Knowledge Graph 장점
- 물리적으로 적은 양의 텍스트로도 필요한 정보 제공 가능
- Entity 간 연결을 통해 직접적인 연결성 확인 가능
- 필요한 정도에 따라 노드의 종류, 관계의 종류 등을 직접 조절 가능
- Knowledge Base Question Answering(KBQA)
- 정답이 있는 자연어 형태의 사실적 질문에 대해 Knowledge base를 통해 정답 entity를 산출하는 태스크
- Knowledge graph를 활용하고 텍스트로 주어진 질문에 대한 답변을 텍스트로 반환한다는 점에서 유사
- KBQA의 일반화된 형태가 Graph RAG
| 항목 | KBQA | GraphRAG |
| 목적 | 구조화된 지식베이스에서 정확한 답 검색 | 그래프 구조를 활용한 검색 증강 생성 |
| 지식 표현 | RDF 트리플, 지식그래프(구조화) | 텍스트 + 그래프 구조(반구조화) |
| 질의 처리 | 자연어 -> SPARQL/논리형식 변환 | 자연어 -> 그래프 검색 + LLM 생성 |
| 답변 형태 | 정확한 팩트/엔티티 | 생성된 자연어 텍스트 |
| 추론 방식 | 논리적 추론(규칙 기반) | 그래프 탐색 + 언어모델 추론 |
| 데이터 소스 | Freebase, DBpedia, Wikidata 등 | 문서 컬렉션 그래프 변환 |
Knowledge Graph and LLM
- LLM으로 Knowledge Graph 만들기
- LLM에 문서별로 입력하여 entity 및 relation으로 구성된 triplet을 생성하라는 prompt 입력
- LLM 통해 생성된 triplet을 모아 전체 지식 그래프 구축
- Knowledge Graph Completion : Triplet 중 하나의 요소를 제외한 후 해당 요소가 무엇일지 예측하는 과업 수행
- LLM에 문서별로 입력하여 entity 및 relation으로 구성된 triplet을 생성하라는 prompt 입력
- Knowledge Graph를 LLM에 입력하기
- 문서 및 passage를 노드화 한 후 언어모델로 노드 임베딩 획득 / 문서 내 구조 또는 노드 임베딩 간 유사도 기반으로 엣지 형성
- 문서를 KG로 표시한 후 Multi-Documnet Question Answering을 수행한다면 GraphRAG와 가장 유사한 형태가 됨

- 쿼리가 주어졌을 때, 가장 유사한 노드를 하나 찾고(1)
- 이 노드와 연결된 그래프 노드들을 탐색하면서 필요한 정보들을 획득
- 참고
Community Detection
- Graph clustering 방식 중 하나, 밀접하게 연결된 노드들의 집합을 찾아내는 작업
- Graph clustering = [ Graph partitioning, Community detection, ... ]
- 기본 가정 : 그래프 상에서 비슷한 노드들은 서로 연결/밀집되어 있을 것이다
- 핵심 개념 : Modularity(↑) = 커뮤니티 내 연결은 많고, 커뮤니티 외 연결이 적을수록 modularity는 높음
- Modularity를 어떻게 정의하고 이를 최적화 하느냐 -> community detection 방법론
- 대표적인 방법론 : Louvain 알고리즘
- 두 단계로 구성
- Local Moving : 각 노드를 modularity를 높이는 커뮤니티로 할당 / greedy search
- Aggregation : 1에서 탐색한 community를 하나의 노드로 간주하여 새로운 그래프로 압축
- 종료 조건
- 1단계에서 더 이상 노드 이동이 일어나지 않음
- 전체 modularity가 증가하지 않음
- 그래프 축소가 되지 않음 = <노드 개수 = community 개수>
- 결과물
- 계층적 구조의 community 및 노드의 community 할당 결정
- 두 단계로 구성
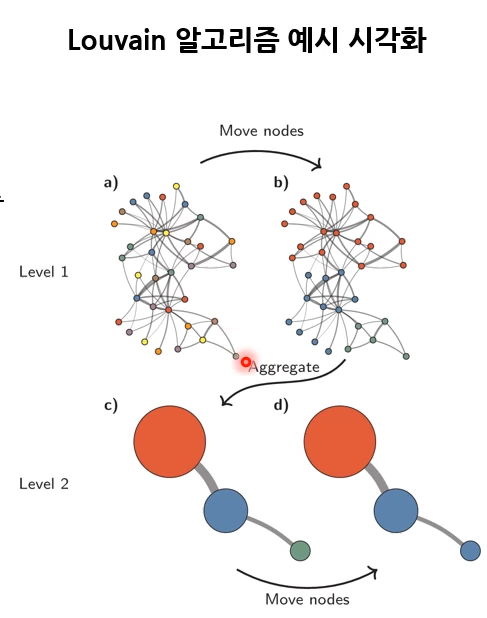

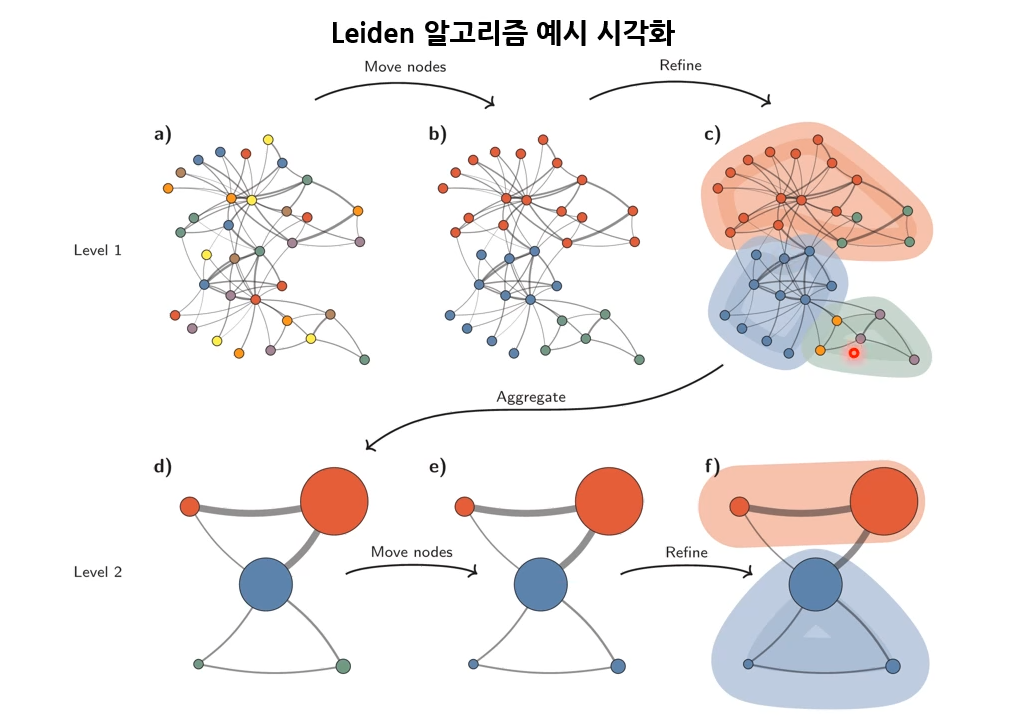
- Leiden 알고리즘
- Louvain 알고리즘의 경우, 전체 community의 modularity에만 초점 맞추어 같은 community에 있는 노드 간에 연결되어 있지 않은 경우 발생함
- Leidan 알고리즘은 모든 커뮤니티가 내부적으로 잘 연결되어 있음을 보장
- 세 단계로 구성
- Local Moving
- Refinement
- 각 community 별로 수행되는 작업
- Community 내의 노드를 개별적인 community로 간주하여, 서로 잘 연결되어 있는 노드들끼리 새로운 community 형성
- 연결되어 있지 않은 노드들은 개별적인 community가
- Aggregation
Sensemaking
- The process by which people give meaning to their collective experiences (위키피디아)
- 연결 관계를 이해하고, 미래를 예측하여 효과적으로 행동하기 위한 동기화된 지속적인 노력
- 조직이 어떻게 불확실한 환경에서 의미를 만들어가는지를 내포하는 개념
- Sensemaking 과정
- 신호 포착(Noticing) : 환경에서 중요한 신호나 변화 인지
- 해석(Interpreting) : 포착된 정보에 의미를 부여하고 기존 지식과 연결
- 행동(Acting) : 해석된 의미에 기반하여 행동 취함
- 반영(Reflectig) : 행동의 결과를 평가하고 새로운 이해 형성
- 데이터 사이언스 관점에서의 sensemaking
- 주어진 정보를 어떻게 연결시키며, 혹은 정보 간의 내재적인 연결관계를 어떻게 찾을 것인가
- 주어진 정보 중에서 어떤 것이 특별히 중요한가(식별성 확보 중요)
- LLM 및 query 활용 시 : query에 가장 적합한/연관 있는 정보는 무엇인가를 식별할 수 있어야 함
Introduction
- 문제 정의
- 일반적인 RAG는 코퍼스 양이 많을 때 global sensemaking 능력이 부족하다
- Global sensemaking : corpus의 전반적인 내용을 바탕으로 진행되는 sensemaking
- 언제 global sensemaking이 필요한가?
- Ex. 문헌 분석 프레임워크
- Q. 2015-2025년 동안 전기차 배터리 또는 배터리 공정 관련 연구 분야에서 인공지능 기술로 해결해고자 했던 과업은 무엇이며 이에 대한 예시를 알려주세요
- Ex. 문헌 분석 프레임워크
- 연구의 기여점
- GraphRAG 제안(A graph-based RAG approach that enables sensemaking over the entirety of a large text corpus)
- 정답이 없는 질문의 답변을 기반으로 global sensemaking 능력을 평가하기 위한 LLM-as-a-judge 기술 응용
- LLM으로 Global sensemaking 평가용 질문 생성
- LLM으로 사전에 정의한 평가 기준을 prompt에 입력하여 평가 진행
2. Methodology
Overview
- Indexing Time & Query Time
- Indexing Time : LLM-derived graph index of source document text
- Query Time :
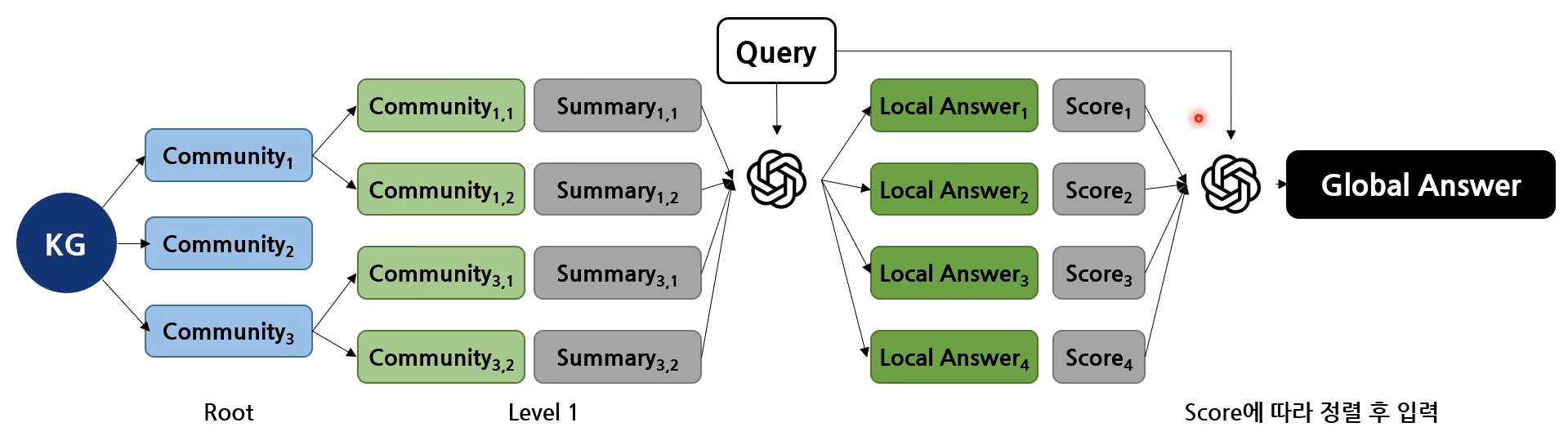
각 community로부터 query와 연관된 요약된 정보를 추출하여 (community answer) 최종적으로 하나의 요약 내용을 형성한 후 query와 함께 prompt에 입력하여 global answer 생성
- GPT-4-turbo로 모든 LLM 통일

- Indexing Time : Document로부터, chunking하고, chunking된 document로부터 각각의 entity와 relationship을 찾음으로써 KG를 생성하게 됨. KG로부터 community detection으로 Graph Community를 만들고, detect된 community별로 community summary라는 텍스트를 생성 (RAG 위한 준비 단계)
- Query Time : query와 Community summary로부터 community answer를 형성, community answer를 종합해서 최종적으로 global answer를 생성
Indexing: Source Documents to Text Chunks
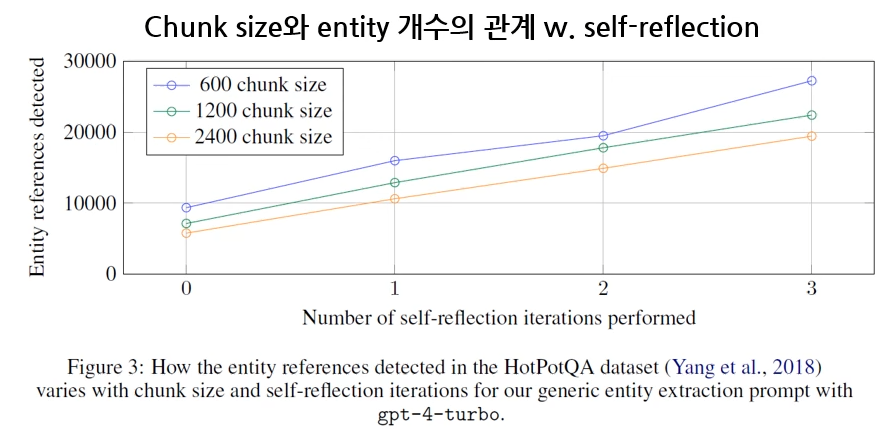
- Chunk size 클 수록 탐색되는 entity 개수 적어짐 (trade-off)
- Chunk size 커질수록, entity와 relation이 중복되고 요약이 되는 현상이 보여
- 실험을 위한 두 개의 데이터셋 chunk 개수 및 사이즈
- Podcast transcription(1M tokens)
- "Behind the Tech with Kevin Scott" 팟캐스트 대본
- 1669개 * 600 tokens with 100-token-overlaps (100토큰씩 겹침.. 이건 무슨 말?)
- New articles(1.7M tokens)
- 2013년 9월 - 2023년 12월까지의 뉴스 기사 / 연예, 경제, 스포츠, 기술, 건강, 과학 등의 분야로 구성
- 3197개 * 600 tokens with 100-token-overlaps
- Podcast transcription(1M tokens)
Indexing: Text Chunks to Entities & Relationships
- Entity의 타입은 문서 및 활용 방식에 따라 변경 가능

- Claim 추출
- Entity에 대한 중요한 사실 / ex. 날짜, 이벤트, 다른 entity와의 interactions

- Self-Reflection
- LLM 스스로 답변에 대해 평가한 후, 필요한 경우 답변을 재생성하도록 유도하는 프롬프팅 기술
- Chunk-size를 크게 하여, 호출 횟수는 줄이면서 탐지되는 entity 수는 더 증가시킬 수 있도록 함

- Entity, Relationship, Claim 통일
- 동일한 entity/relationship/claim 이더라도, chunk마다 내용이 달라 description도 상이할 수 있음
- 동일한 entity/relationship/claim에 대한 description들을 모두 모아 하나로 요약
- Relationship의 등장 횟수로 edge weight 설정
- 공식 코드에서 networkx, pandas의 DataFrame으로 그래프 관리 함

Indexing: Knowledge Graph to Graph Community
- Leiden 알고리즘으로 community detection 실시
- Two-level Community 시각화 예시
- 색으로 community 구분
- Community 내 degree 합이 클수록 노드 사이즈 커짐

Indexing: Graph Communities to Community Summaries
- 리포트 형식으로 community의 정보를 요약(summarization) 함
- Community report prompt
- LLM 입력 길이 제한으로 community의 rank 정하여 차례대로 입력
- Leaf level community: community 내 edge 수의 합을 기준으로 중요도 정함
- 상위 level community: sub-community의 summary 길이가 짧은 것부터 입력

Query: Community Summaries -> Community Answers -> Global Answer
- Prepare community summaries
- Community summaries 랜덤 셔플링 후 사전 정의된 길이만큼 chunking
- Map community answers
- 각 community summary 기반 답변 생성(Local answer)
- 생성 시 각 답변이 query에 얼마나 도움이 될지(how helpful) 100점 만점으로 score 산출하도록 함
- Reduce to global answer
- 높은 점수부터 local answer가 token limit size에 맞추어 prompt에 입력되어 최종 답변(Global answer) 생성

3. Experiments
Global Sensemaking Question Generation
정답이 없는 질문에 대한 답변을 평가하기 위한 LLM-as-a-judge 과정
중, 질문을 생성하는 과정
- Dataset(Corpus)에 적합한 global sensemaking 질문들을 LLM 통해 생성
- 특정 사용자의 상황(role)을 가정하고 이에 대한 정보 입력하여 persona 정보 생성
- 각 persona 별로 수행하고 싶은 태스크 입력 / 단, 코드 상에서는 1에 task 정보를 입력한 후 persona 산출되도록 함
- 1, 2에 대한 정보를 입력하여 원하는 개수만큼 질문 생성
- 다만, 사용자 정보를 어떻게 사전에 정의/설정 했는지에 대해서는 나오지 않음

Criteria for Evaluating Global Sensemaking
- 생성한 global sensemaking 질문들은 정답(golden standard answer)이 없음
- 동일한 query에 대한 비교 방법론들 별 답변을 LLM으로 직접 비교하도록 함
- Experiment 1
- 평가 기준
- Comprehensiveness : 답변이 질문의 모든 측면과 세부사항을 다루기 위해 얼마나 상세한 내용을 제공하는가?
- Diversity : 답변이 해당 질문에 대해 서로 다른 관점과 통찰을 제공함에 있어 얼마나 다채롭고 풍부한가?
- Empowerment : 답변이 독자로 하여금 해당 주제에 대해 이해하고 정보에 기반한 판단을 내리는 데 얼마나 도움이 되는가?
- Directness : 얼마나 간결하고 정확하게 답변을 제공하는가?
- Directness는 Comprehensive와 Diversity와 trade-off 관계임
- 네 기준 모두에 대해 높은 점수 받을 수 없는 상황
- 평가 기준에 대한 근거 또는 참고 문헌 별도 없음
- 평가 방법
- 서로 다른 두 방법론으로 획득한 답변으로 1 vs 1 대결하여 승/패/무승부 결정하도록 함 & 총 5번 진행
- 단, Condition A (vs Condition B) = 2승 2무 1패인 경우 무승부로 처리
-> Majority voting이라고 명시, 발표자 의견은 '옳은 승패 결정은 아니다' ... 위 경우 '승'으로 판별
- 단, Condition A (vs Condition B) = 2승 2무 1패인 경우 무승부로 처리
- 서로 다른 두 방법론으로 획득한 답변으로 1 vs 1 대결하여 승/패/무승부 결정하도록 함 & 총 5번 진행
- 평가 기준

Conditions(Baselines)
- Community detection을 4개의 level로 구성한 후 각 level로부터 얻어지는 community summaries 비교
- C0(Root) > C1 > C2 > C3
- Text Source(TS): community의 요약문이 아닌 실제 문서들의 요약문으로 진행
- Entity와 relationship까지 구축한 상황
- 일반 RAG처럼 문서들을 chunking한 후 랜덤 셔플링 진행
- Query 임베딩과 유사한 임베딩의 entity 최대 20개 추출
- 추출된 entity가 포함된 chunks 선택 ... chunk가 하나의 community summary
- Chunk = (sub) community summary
- 일반적인 RAG
- Text chunk를 벡터화한 후 query와 유사도 높은 임베딩의 chunk 선택 후 prompt에 입력
Configuration
- 모든 생성문(community summaries, community/local answer, global answer 등)의 길이 8k로 설정
- Graph indexing
- 컴퓨터 사양 : 16GB RAM, Intel(R) Xeon(R) Platinum 8171M CPU @ 2.60GHz(클라우드 활용)
- 소요 시간 예시 : chunk size 600 토큰 설정 시 281분 소요됨
- LLM: GPT-4-turbo | 속도 제한 : 2M Tokens Per Minute(TPM), 10k Request Per Minute(RPM)
Results - Experiments 1
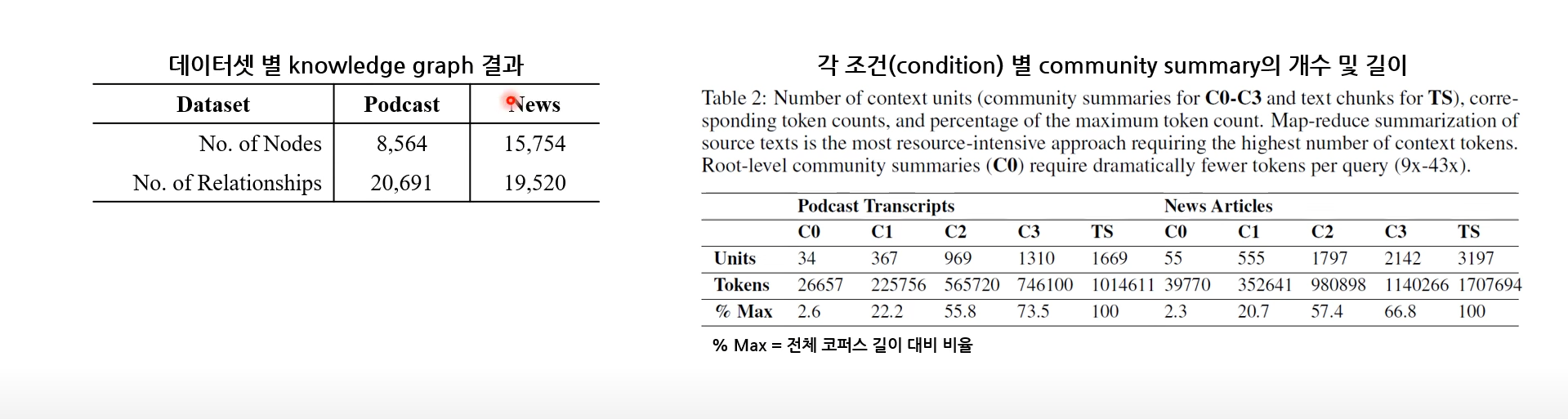
- Root level이 될 수록 사용되는 community summary의 길이가 짧아지기에 % Max 비율이 제일 작아짐
- 하위 level이 될 수록, community 갯수가 늘어나서 community summary 길어지고 비율 증가
- Global approaches vs 일반 RAG
- Comprehensiveness, diversity 기준에서 GraphRAG가 월등히 우수한 성능 보임
- Directness 기준으로는 일반 RAG가 근소하게 더 우세한 모습 보임

- 일반 RAG가 Directness에서 근소하게 우수함을 알 수 있음 > 평가 기준이 잘 적용되고 있음
- Empowerment 얼마나 답변이 유용한지에 대한 평가, 특별히 우수한 성능의 조건은 없음
- C0가 다른 조건 대비 약세 / SS, TS가 평균적으로 근소하게 우세
- 예시, 인용문 등의 직접적인 정보가 주어졌을 때, 판단의 근거로 활용 가능할 것이기에 문서를 직접 활용하는 것이 유리
- Community summaries vs. source texts
- Comprehensiveness, Diversity : 유의검정 결과, community summaries 활용 시 더 좋은 모습 / C0 제외(유의하게 더 좋은 모습 보이지는 않음)
- 특히 C0의 경우 DB로 활용되는 토큰 수도 매우 적고(2.6%), 성능은 훨씬 높음
Experiments 2
- 답변으로부터 획득되는 claim을 통한 comprehensiveness와 diversity 비교
- 발표자 첨언 : Indexing 과정에서 구한 claim 활용법에 대해서는 언급 없음
- 생성된 답변으로부터 Claimfy(LLM 기반의 claim 추출기)를 통해 claim 추출함
- Claim 기반의 comprehensiveness와 diversity 측정
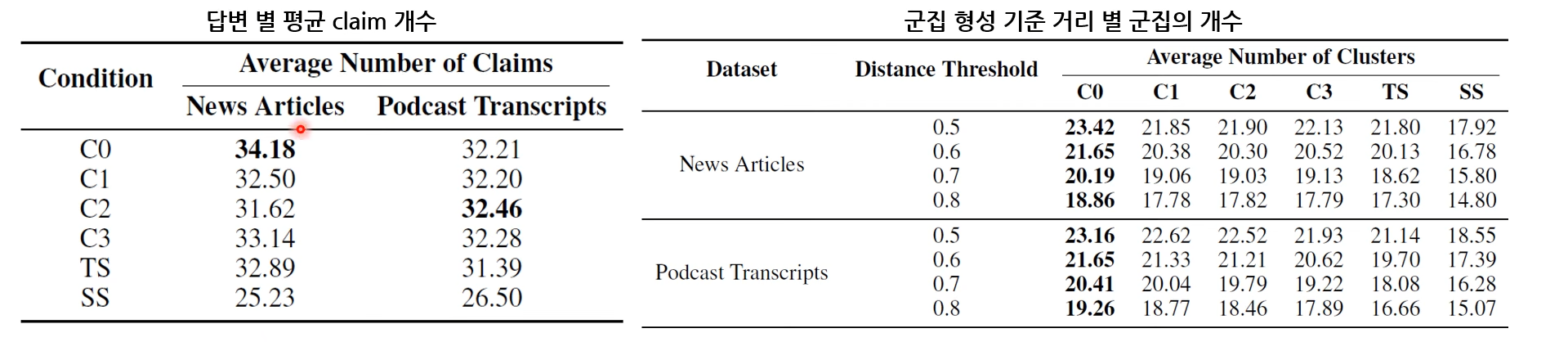
- Comprehensiveness: 답변 별로 추출되는 평균 claim 수(얼마나 디테일하게 claim을 잡고 있느냐, claim을 기준으로 clustering 적용했을 때 얼마나 많은 cluster를 발견할 수 있느냐=얼마나 다양한 주제를 다루고 있느냐)
- Diversity : 답변 별로 추출되는 claim 대상으로 계층적 군집화 진행했을 때 생성되는 평균 군집의 수
- 텍스트 간 거리 지표 : 1 - ROUGE L
- Claim 개수
- Podcast, News 데이터셋 모두 C0~C3 & TS >> SS
- 클러스터 개수
- Podcast 데이터셋 : C0~C3 & Ts >> SS
- C1~C3의 경우 특정 distance threshold에서만 유의미한 결과 보임
- Podcast 데이터셋 : C0~C3 & Ts >> SS
- 그러나, 유의검정 결과, 두 데이터셋에 대해서 각 조건 마다의 유의미한 차이는 보이지 않는 것으로 확인
- 그래서, Experiments 1과의 결과와 align 되는지 확인
- Experiment 1에서 승패가 확실히 갈린 경우(승 또는 패가 3번 이상인 경우) : Comprehensiveness = 33% / Diversity = 39%
- 그 중, Experiment 2와의 결과가 부합되는 경우 : Comprehensiveness = 78% / Diversity = 69-70% , 높은 alignment 보임
Discussion
- 한계점
- 일반화 성능을 구체적으로 확인하기 위해서는 보다 다양한 도메인의 corpus 대상으로 실험 해볼 필요 존재
- 평가 기준 중 'fabrication rates(환각률, 허위정보생성률)' 등 포함 가능
- 향후 연구
- Hybrid RAG scheme
- GraphRAG는 순전히 텍스트 기반으로 진행됨
- 기존 RAG 방식처럼, community summaries 등을 임베딩 시켜, 벡터간 비교를 통한 정보 탐색 방안 적용 기능
- Hybrid RAG scheme
- Global approach 통해 '일부가 전체를 대표하는 상황' 면할 수 있음
4. Materials
- Microsoft 공식 깃헙
- Microsoft 공식 API 문서
- Neo4j 기반 GraphRAG 위키독스(Neo4j : 그래프 기반 데이터베이스에 특화됨)
- Neo4j 제공 무로 textbook
5. Conclusions
- 문서 및 정보를 지식 그래프 구조로 저장한 후, community detection 기법을 통해 그래프 구조를 보존한 채 정보 검색 및 증강을 진행할 수 있는 프레임워크
- 일반적인 검색 증강 방법론 대비 보유하고 있는 전체 문서(database)에 대한 종합적인(global) 내용을 잘 검색할 수 있음
- 평가 과정 중 persona와 task에 따른 질문을 생성한 방식 = 좋은 아이디
'NLP > 논문' 카테고리의 다른 글
| LogLLM: Log-based Anomaly Detection Using Large Language Models (4) | 2025.06.30 |
|---|---|
| Efficient Continual Pre-training for Building Domain Specific Large Language Models(일단 해석만) (0) | 2025.05.26 |